局部敏感哈希 - SimHash¶
2018-06-02
LSH, SimHash
上一篇记录了MinHash的基本原理,这篇讲介绍另一个局部敏感哈希算法——SimHash。
与MinHash相似,SimHash的基本原理也是通过对原始数据进行降维及0/1化,进而使用海明距离比对,找出海明距离在n以内的相似文档。
算法示例¶
SimHash的算法过各也比较简单,以中文NLP为例,算法流程如下:
分词,把需要判断文本分词形成这个文章的特征单词。最后形成去掉噪音词的单词序列并为每个词加上权重,我们假设权重分为5个级别(1~5)。比如:“ 美国“51区”雇员称内部有9架飞碟,曾看见灰色外星人 ” ==> 分词后为 “ 美国(4) 51区(5) 雇员(3) 称(1) 内部(2) 有(1) 9架(3) 飞碟(5) 曾(1) 看见(3) 灰色(4) 外星人(5)”,括号里是代表单词在整个句子里重要程度,数字越大越重要。
hash,通过hash算法把每个词变成hash值,比如“美国”通过hash算法计算为 100101,“51区”通过hash算法计算为 101011。这样我们的字符串就变成了一串串数字,还记得文章开头说过的吗,要把文章变为数字计算才能提高相似度计算性能,现在是降维过程进行时。
加权,通过 2步骤的hash生成结果,需要按照单词的权重形成加权数字串,比如“美国”的hash值为“100101”,通过加权计算为“4 -4 -4 4 -4 4”;“51区”的hash值为“101011”,通过加权计算为 “ 5 -5 5 -5 5 5”。
合并,把上面各个单词算出来的序列值累加,变成只有一个序列串。比如 “美国”的 “4 -4 -4 4 -4 4”,“51区”的 “ 5 -5 5 -5 5 5”, 把每一位进行累加, “4+5 -4+-5 -4+5 4+-5 -4+5 4+5” ==》 “9 -9 1 -1 1 9”。这里作为示例只算了两个单词的,真实计算需要把所有单词的序列串累加。
降维,把4步算出来的 “9 -9 1 -1 1 9” 变成 0 1 串,形成我们最终的simhash签名。 如果每一位大于0 记为 1,小于0 记为 0。最后算出结果为:“1 0 1 0 1 1”。
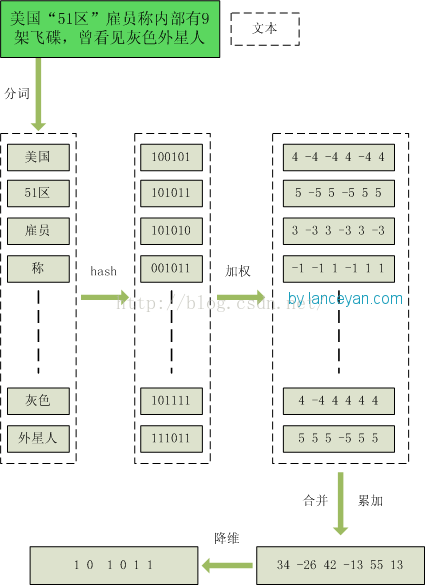
算法过程还是比较简单明了的,在实际的应用中,可以根据实际情况进行应用场景的适应:
如:如果要处理的文本较长,第一步的分词过程,可以改为一个提取关键词的过程;第三步的加权,“权”从何来,可以算文档的tf-idf,
抑或是textrank的权重,或者粗暴的对词性赋权。
JenkinsHash¶
第二步Hash过程,通常采用Jenkins hash算法,memcached默认使用了此算法进行哈希。
Jenkins hash 可以产生很好的分布,但其缺点是相比其他常见的hash算法更耗时。
import numpy as np
def rshift_zero_padded(val, n):
"""Zero-padded right shift"""
return (val % 0x100000000) >> n
def _mix(a, b, c):
"""
mix 3 32-bit values reversibly.
For every delta with one or two bit set, and the deltas of all three
high bits or all three low bits, whether the original value of a,b,c
is almost all zero or is uniformly distributed,
* If mix() is run forward or backward, at least 32 bits in a,b,c
have at least 1/4 probability of changing.
* If mix() is run forward, every bit of c will change between 1/3 and
2/3 of the time. (Well, 22/100 and 78/100 for some 2-bit deltas.)
mix() was built out of 36 single-cycle latency instructions in a
structure that could supported 2x parallelism, like so:
a -= b;
a -= c; x = (c>>13);
b -= c; a ^= x;
b -= a; x = (a<<8);
c -= a; b ^= x;
c -= b; x = (b>>13);
"""
"""
# 1st set
a -= b; a -= c; a ^= (c>>13);
b -= c; b -= a; b ^= (a<<8);
c -= a; c -= b; c ^= (b>>13);
# 2nd set
a -= b; a -= c; a ^= (c>>12);
b -= c; b -= a; b ^= (a<<16);
c -= a; c -= b; c ^= (b>>5);
# 3rd set
a -= b; a -= c; a ^= (c>>3);
b -= c; b -= a; b ^= (a<<10);
c -= a; c -= b; c ^= (b>>15);
"""
# 1st set
a -= b
a -= c
a ^= (rshift_zero_padded(c, 13))
b -= c
b -= a
b ^= (a << 8)
c -= a
c -= b
c ^= rshift_zero_padded(b, 13)
# 2nd set
a -= b
a -= c
a ^= rshift_zero_padded(c, 12)
b -= c
b -= a
b ^= a << 16
c -= a
c -= b
c ^= rshift_zero_padded(b, 5)
# Third set
a -= b
a -= c
a ^= rshift_zero_padded(c, 3)
b -= c
b -= a
b ^= a << 10
c -= a
c -= b
c ^= rshift_zero_padded(b, 15)
return a, b, c
def _hash(input_data, initVal=0):
"""
hash() -- hash a variable-length key into a 32-bit value
k : the key (the unaligned variable-length array of bytes)
len : the length of the key, counting by bytes
level : can be any 4-byte value
Returns a 32-bit value. Every bit of the key affects every bit of
the return value. Every 1-bit and 2-bit delta achieves avalanche.
About 36+6len instructions.
The best hash table sizes are powers of 2. There is no need to do
mod a prime (mod is so slow!). If you need less than 32 bits,
use a bitmask. For example, if you need only 10 bits, do
h = (h & hashmask(10));
In which case, the hash table should have hashsize(10) elements.
If you are hashing n strings (ub1 **)k, do it like this:
for (i=0, h=0; i<n; ++i) h = hash( k[i], len[i], h);
By Bob Jenkins, 1996. bob_jenkins@burtleburtle.net. You may use this
code any way you wish, private, educational, or commercial. It's free.
See http://burtleburtle.net/bob/hash/evahash.html
Use for hash table lookup, or anything where one collision in 2^32 is
acceptable. Do NOT use for cryptographic purposes.
"""
data = bytes(input_data, encoding='ascii')
len_pos = len(data)
length = len(data)
if length == 0:
return 0
a = 0x9e3779b9
b = 0x9e3779b9
c = initVal
p = 0
while len_pos >= 12:
a += ((data[p + 0]) + ((data[p + 1]) << 8) + ((data[p + 2]) << 16) + ((data[p + 3]) << 24))
b += ((data[p + 4]) + ((data[p + 5]) << 8) + ((data[p + 6]) << 16) + ((data[p + 7]) << 24))
c += ((data[p + 8]) + ((data[p + 9]) << 8) + ((data[p + 10]) << 16) + ((data[p + 11]) << 24))
q = _mix(a, b, c)
a = q[0]
b = q[1]
c = q[2]
p += 12
len_pos -= 12
c += length
if len_pos >= 11:
c += (data[p + 10]) << 24
if len_pos >= 10:
c += (data[p + 9]) << 16
if len_pos >= 9:
c += (data[p + 8]) << 8
# the first byte of c is reserved for the length
if len_pos >= 8:
b += (data[p + 7]) << 24
if len_pos >= 7:
b += (data[p + 6]) << 16
if len_pos >= 6:
b += (data[p + 5]) << 8
if len_pos >= 5:
b += (data[p + 4])
if len_pos >= 4:
a += (data[p + 3]) << 24
if len_pos >= 3:
a += (data[p + 2]) << 16
if len_pos >= 2:
a += (data[p + 1]) << 8
if len_pos >= 1:
a += (data[p + 0])
q = _mix(a, b, c)
a = q[0]
b = q[1]
c = q[2]
return rshift_zero_padded(c, 0)
def lookup2(data: any) -> int:
"""Python implementation of Jenkins hash function lookup2"""
return _hash(data)
def ooat(key: any) -> int:
"""Python implementation of Jenkins hash one-at-a-time function via numpy"""
key_hash = 0
for c in key:
key_hash += np.int32(ord(c))
key_hash += np.int32(key_hash) << np.int32(10)
key_hash = np.int32(key_hash) ^ (np.int32(key_hash) >> np.int32(6))
key_hash += key_hash << np.int32(3)
key_hash ^= key_hash >> np.int32(11) # Don't need to cast key_hash to int32 here I guess
key_hash += key_hash << np.int32(15)
return np.uint32(key_hash) >> np.uint32(0)
print(bin(ooat('中国好声音')))
print(bin(ooat('今晚')))
print(bin(ooat('开播')))
海明距离¶
最后通过计算海明距离(两个数异或时,只有在两个比较的位不同时其结果是1 ,否则结果为0,两个二进制“异或”后得到1的个数即为海明距离的大小。),高效计算二进制序列中1的个数代码如下:
def isEqual(lhs, rhs, n = 3):
cnt = 0;
lhs ^= rhs;
while lhs and cnt <= n:
lhs &= lhs - 1;
cnt += 1
if cnt <= n:
return True;
return False;
print(isEqual(0b100001, 0b100001))
print(isEqual(0b111101, 0b100001))
print(isEqual(0b111101, 0b100001, 2))
面对海量数据,如有上亿个网页的SimHash结果,对数据进行逐个比对效率还是比较低的,通过以空间换时间的方式,可以达到明显的性能提高。
假如我们认为海明距离在3以内的具有很高的相似性,那样我们就可以用到鸽巢原理(也叫抽屉原理),如果将simhash分成4段的话,那么至少有一段完全相等的情况下才能满足海明距离在3以内。同理将simhash分为6段,那么至少要满足三段完全相等,以此类推。
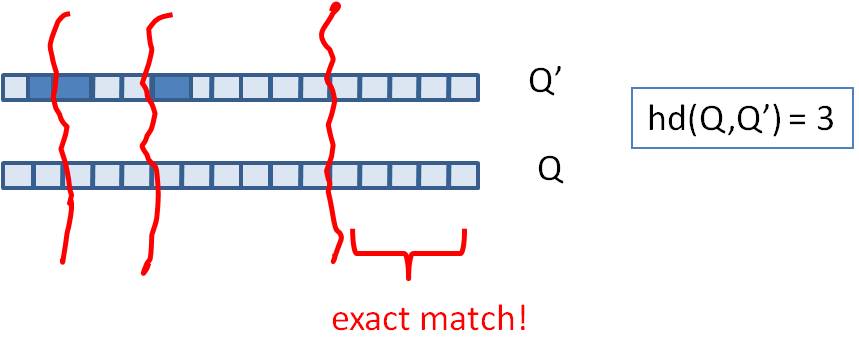
可以使用相等的部分做为hash的key,然后将具体的simhash值依次链接到value中,方便计算具体汉明距离。
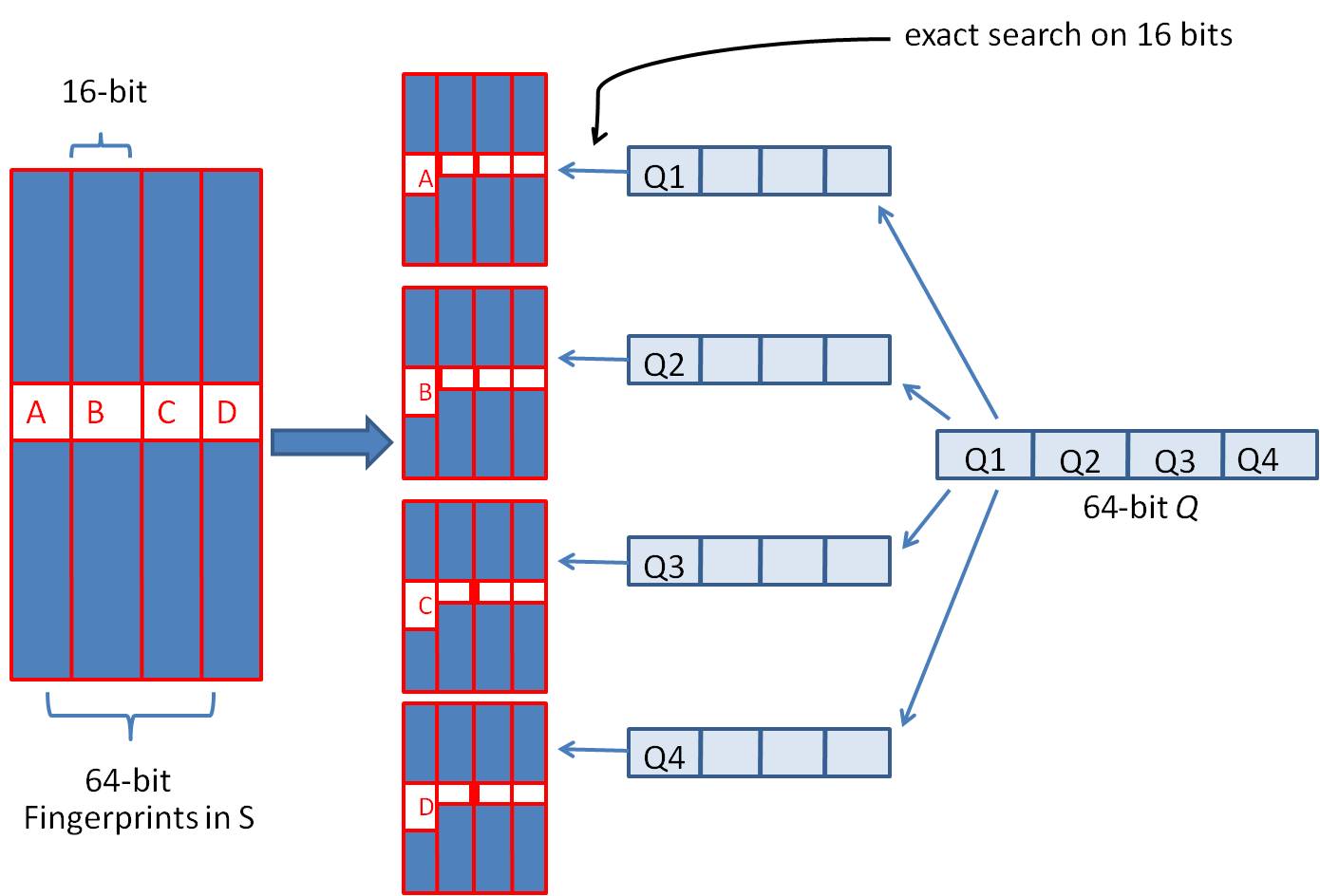
- 将64位的二进制串等分成四块
- 调整上述64位二进制,将任意一块作为前16位,总共有四种组合,生成四份table
- 采用精确匹配的方式查找前16位
- 如果样本库中存有$2^{34}$(差不多10亿)的哈希指纹,则每个table返回$2^{34-16}=262144$个候选结果,大大减少了海明距离的计算成本
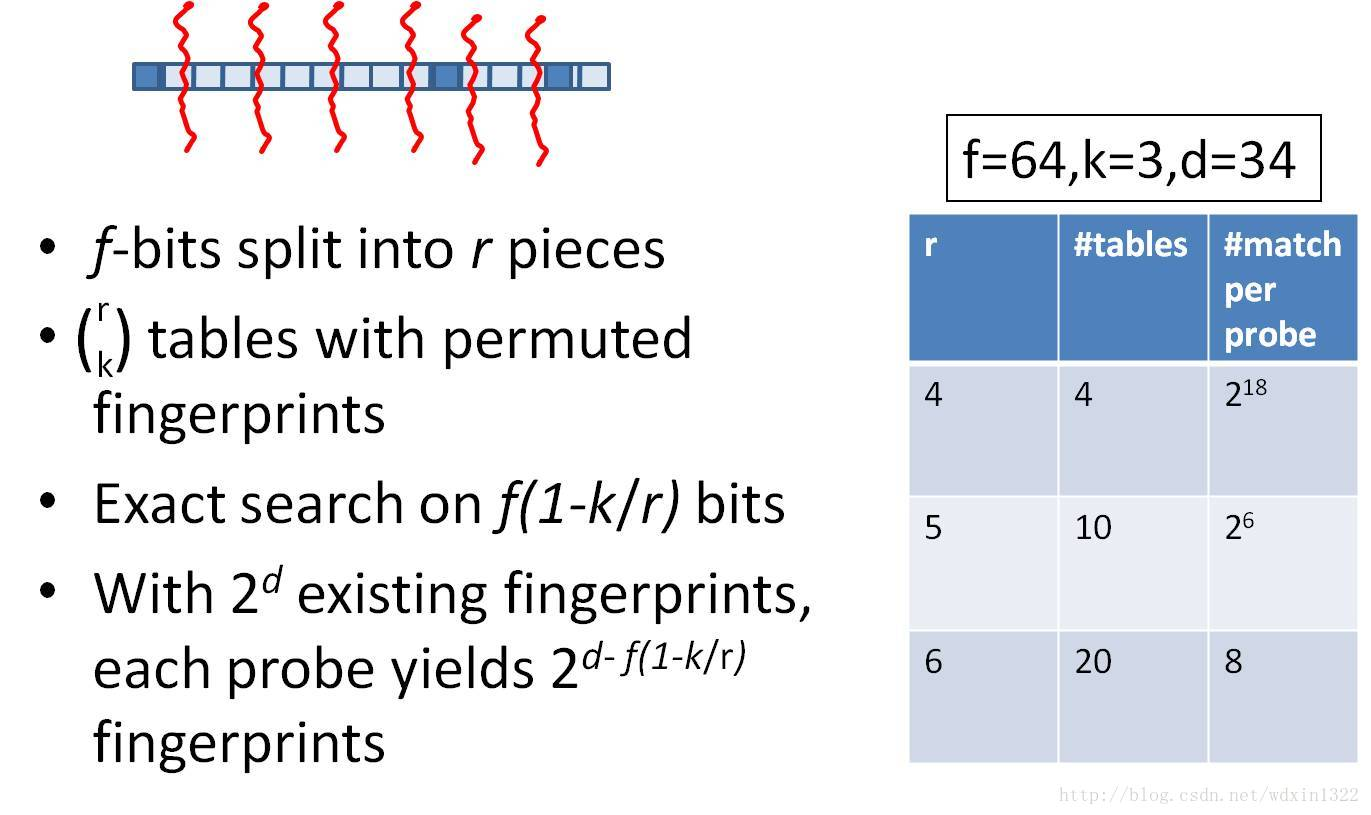
可以将这种方法拓展成多种配置,不过,请记住,table的数量与每个table返回的结果呈此消彼长的关系,也就是说,时间效率与空间效率不可兼得,参看下图:
总结¶
Simhash是通过设计一个hash方法,使要内容相近item生成的hash签名也相近,hash签名的相近程度,也能反映出item间的相似程度。
从降维的脚度看,通过将item预处理为simhash值后,通过计算两者的汉明距离计算相似度。