局部敏感哈希 - MinHash¶
2018-05-15
LSH, MinHash
假设我们需要从一堆数据中,找出与某个数据最相似(相近)的一个或多个数据。
在小数据/低维数据中,我们可以拿输入的数据对库中所有的数据逐个比对,进而找多个或一个与之最相近的数据。
而在海量高维数据的场景下,想通过这样的线性查找(Linear Search)来完成显然是不现实的(耗时太长)。
为此,一些类似索引的技术来加快查找过程,通常这类技术称为最近邻查找(Nearest Neighbor,AN),例如K-d tree;或近似最近邻查找(Approximate Nearest Neighbor, ANN),例如K-d tree with BBF, Randomized Kd-trees, Hierarchical K-means Tree。而LSH是ANN中的一类方法。
LSH¶

局部敏感哈希(Locality-Sensitive Hashing, LSH) 是一种解决在海量的高维数据集中查找与查询数据点(query data point)近似最相邻的某个或某些数据点的方法。
基本思想是:将原始数据空间中的两个相邻数据点通过相同的映射或投影变换(projection)后,这两个数据点在新的数据空间中仍然相邻的概率很大,而不相邻的数据点被映射到同一个桶的概率很小。也就是说,如果我们对原始数据进行一些hash映射后,我们希望原先相邻的两个数据能够被hash到相同的桶内,具有相同的桶号。对原始数据集合中所有的数据都进行hash映射后,我们就得到了一个hash table,这些原始数据集被分散到了hash table的桶内,每个桶会落入一些原始数据,属于同一个桶内的数据就有很大可能是相邻的,当然也存在不相邻的数据被hash到了同一个桶内。
因此,如果我们能够找到这样一些hash functions,使得经过它们的哈希映射变换后,原始空间中相邻的数据落入相同的桶内的话,那么我们在该数据集合中进行近邻查找就变得容易了,我们只需要将查询数据进行哈希映射得到其桶号,然后取出该桶号对应桶内的所有数据,再进行线性匹配即可查找到与查询数据相邻的数据。
需要注意的是,LSH并不能保证一定能够查找到与query data point最相邻的数据,而是减少需要匹配的数据点个数的同时保证查找到最近邻的数据点的概率很大。
下面将介绍两种常见的LSH算法—— MinHash 和 SimHash。
MinHash¶
Minhash[1] 最开始提出是为了解决搜索引擎中网页库的查重问题,即看两个网页内容是否相似。
Minhash 使用 Jaccard相似度来度量两个集合的相似度.
$$J(A, B)=\frac{|A \cap B|}{|A \cup B|}$$举个例子¶
假设有一个输入矩阵如下:

我们对这个矩阵的每一行标注一个号码,就是紫色的这个部分,根据输入矩阵的第一个出现1的行数,可得特征值是[3, 1, 1, 2]
同理,打乱原来序号,可以得到更多的特征值(如橙色和绿色部分所示):
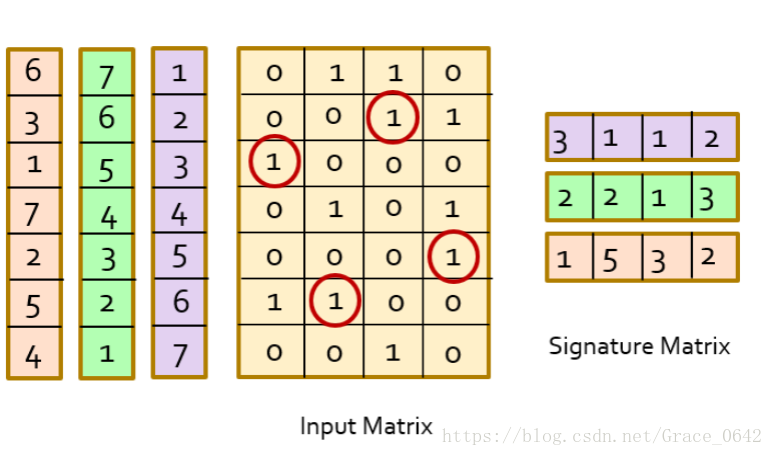
我们利用这个singnature matrix的相似性(Jaccard similarity)就可以来表示我们的这个input matrix 的相似性。
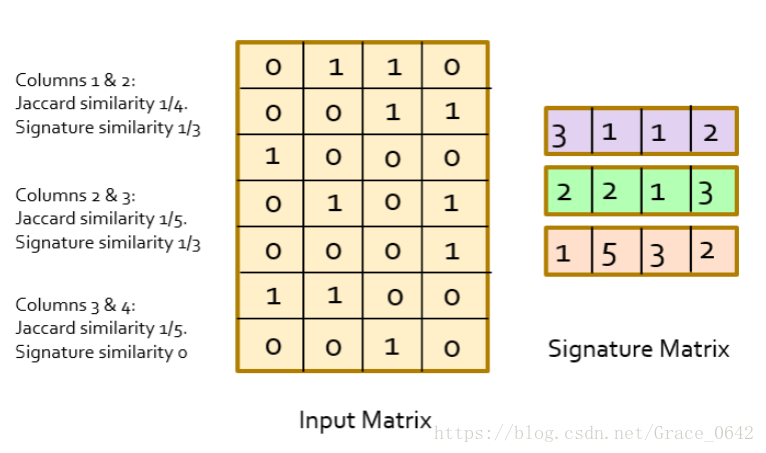
上面我们计算分析的例子发现其实我们可以用signature matrix 中hash值的相似性来表示我们的样本的相似性。
对于两个document,在Min-Hashing方法中,它们hash值相等的概率等于它们降维前的Jaccard相似度。
证明¶
设有一个词项x(就是Signature Matrix中的行),它满足下式:
$$π(x)=min(π(C_1∪C_2))$$就是说,词项x被置换之后的位置,和$C_1$,$C_2$两列并起来(就是把两列对应位置的值求或)的结果的置换中第一个是1的行的位置相同。那么有下面的式子成立:
$$π(x)=min(π(C_1))\ if\ x∈C_1,\ or\ π(x)=min(π(C_2))\ if\ x∈C_2$$就是说x这个词项要么出现在$C_1$中(就是说$C_1$中对应行的值为1),要么出现在$C_2$中,或者都出现。这个应该很好理解,因为那个1肯定是从$C_1$,$C_2$中来的。
那么词项x同时出现在$C_1$,$C_2$中(就是$C_1$,$C_2$中词项x对应的行处的值是1)的概率,就等于x属于$C_1$与$C_2$的交集的概率。 这也很好理解,属于它们的交集,就是同时出现了嘛。 那么现在问题是:已知x属于$C_1$与$C_2$的并集,那么x属于$C_1$与$C_2$的交集的概率是多少? 其实也很好算,就是看看它的交集有多大,并集有多大,那么x属于并集的概率就是交集的大小比上并集的大小,而交集的大小比上并集的大小, 不就是Jaccard相似度吗?于是有下式:
$$Pr[min(π(C_1))=min(π(C_2))]=J(A, B)=|C_1∩C_2|/|C_1∪C_2|=sim(C_1,C_2)$$又因为当初我们的hash function就是
$$hπ(C)=minπ(C)$$往上式代入,
$$Pr[hπ(C_1)=hπ(C_2)]=sim(C_1,C_2)$$简单代码如下:
import random
def sigGen(matrix):
"""
* generate the signature vector
:param matrix: a ndarray var
:return a signature vector: a list var
"""
# the row sequence set
seqSet = [i for i in range(matrix.shape[0])]
# initialize the sig vector as [-1, -1, ..., -1]
result = [-1 for i in range(matrix.shape[1])]
count = 0
while len(seqSet) > 0:
# choose a row of matrix randomly
randomSeq = random.choice(seqSet)
for i in range(matrix.shape[1]):
if matrix[randomSeq][i] != 0 and result[i] == -1:
result[i] = randomSeq
count += 1
if count == matrix.shape[1]:
break
seqSet.remove(randomSeq)
# return a list
return result
def sigMatrixGen(input_matrix, n):
"""
generate the sig matrix
:param input_matrix: naarray var
:param n: the row number of sig matrix which we set
:return sig matrix: ndarray var
"""
result = []
for i in range(n):
sig = sigGen(input_matrix)
result.append(sig)
# return a ndarray
print("\nsig matrix:")
print(np.array(result))
print()
return np.array(result)
import numpy as np
mat = np.array([[0, 1, 1, 0], [0, 0, 1, 1], [1, 0, 0, 0], [0, 1, 0, 1], [0, 0, 0, 1], [1, 1, 0, 0], [0, 0, 1, 0]])
print("input:")
print(mat)
sigMatrixGen(mat, 4)
Hashing¶
上面的例子只能针对数据集比较小的情况才考虑,假设现在有10亿行的数据,使用上边的方法进行处理显然是不行的(内存与排序复杂度)。
但从上边例子可以看出,签名矩阵的长度越长的话,出错的机会或者说相似的机会就比较小。
我们没有必要挑选比较所有的行,我们只要保证我们的签名矩阵的长度合理就可以了。
基于以上,可以做以下调整:
不用对所有的行进行一个随机的排序,挑选n个不同的哈希函数来对行号进行计算就可以得到新的数据,这个数据就代表原先的行号变更出来的行号,可以看成是对整个矩阵的行进行洗牌。(其实这样的hash函数很难找到,因为可能是会存在hash值的碰撞,但是这个不影响这个算法的执行。)
引入一个Slot的值M,M的初始值是无穷大。我们有100个hash函数我们这么来表示我们的hash函数hi, i的取值是从1 到100 的,我们用hash函数hi计算得到一个hash值,如果我们的样本,也就是某一列的某一行是1,而且这个计算出来的Hash值如果比我们的M值要小,那么M就保存着我们计算出来的较小的hash 值,实际上就是我们默认排列出来较小的行号。伪代码如下:
for each hash function hi do
compute hi (r)
for each column c
if c has 1 in row r
for each hash function hi do
if hi (r) is smaller than M(i, c) then
M(i, c) := hi (r);
假设输入为:

选取两个hash函数h(x)与g(x):
$$h(x)=x\ mod\ 5\\ g(x)=(2x+1)\ mod\ 5$$计算过程如下:

最终得于Matrix M为$\begin{bmatrix} 0 & 1 \\ 1 & 2 \end{bmatrix}$.
Buckets¶
对于signature matrix ,需要对这个hash 得到的列再进行Hash ,这个时候要让这些元素映射到不同的bucket中。 (注意,这里的hash 函数可以用一些比较传统的hash 函数) 这样我们认为这些列映射到我们相同的buckets 中的就是我们的候选的相似的对,或者说是我们候选可能相似的样本。

每一列可以看成是一个样本的签名,就是图中的粉红色的条形的部分,就是一列,这一列就是样本中的一个签名或者说是样本的特征值,指纹。然后把这个矩阵划分成了b 个bands 也就是b个条状。 每一条含有r行。
对每一个signature 分段之后的每一个band 计算一个Hash值,然后让它映射到一个长度为k的bucket里面。k要设置的尽量的大一些。这样子是为了减少碰撞的发生。
候选的candidate就是我们认为可能相似的样本就是那些列的hash值被映射到同一个bucket 里面的
通过调节b以及r能够捕捉到大多数的相似的pair ,但是很难捕捉到不相似的pair。
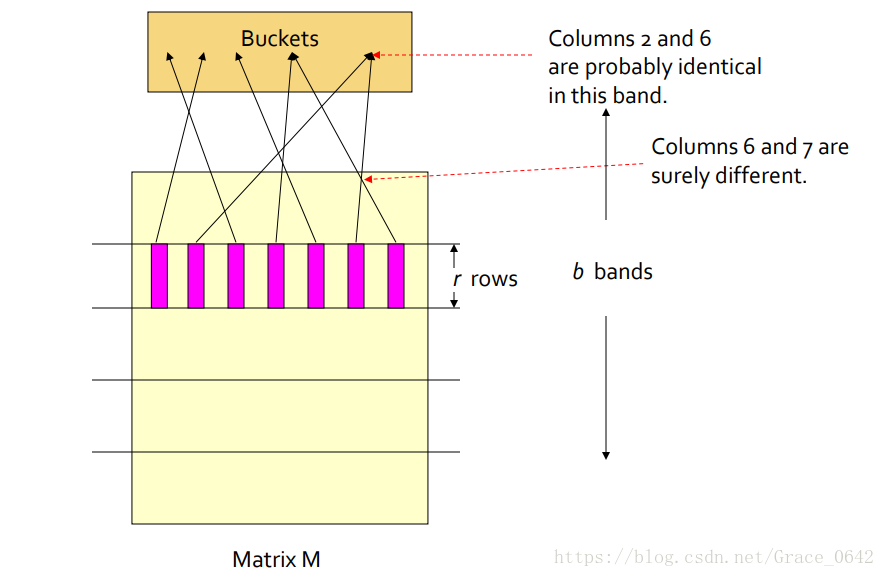
第二列和第六列经过计算一个Hash值之后被映射到了同一个桶里面,这个时候可以认为这两个band 很有可能是相同的。当然也有极小的概率是发生了碰撞。
假设$C_1$和$C_2$有80%的相似度, 在这里设置一个Matrix M 它有100 行,把这个矩阵分成了20 个bands 每一个band 里面都有5 行(r)
那么$C_1$ 以及$C_2$ 在某个特定的band 里面相似的概率
$$(0.8)^5 = 0.328$$在任何一个band 都不相似的概率是:
$$(1-0.328)^{20} = 0.00035$$也就是如果我们设置相似度的阈值是80% 那么它的false nagatives 的概率约为1/3000。
再看以下这个例子:

实际情况是这样的:

对于两个文档的任意一个band来说,这两个band值相同的概率是:$s^r$,其中$s∈[0,1]$是这两个文档的相似度。
也就是说,这两个band不相同的概率是$(1−s^r)$
这两个文档一共存在b个band,这b个band都不相同的概率是$(1−s^r)^b$
所以说,这b个band至少有一个相同的概率是$1−(1−s^r)^b$
这样的方法称为"AND then OR",它是先要求每个band的所有对应元素必须都相同,再要求多个band中至少有一个相同。符合这两条,才能发生hash碰撞
简单代码如下:
import hashlib
def minHash(input_matrix, b, r):
"""
map the sim vector into same hash bucket
:param input_matrix:
:param b: the number of bands
:param r: the row number of a band
:return the hash bucket: a dictionary, key is hash value, value is column number
"""
hashBuckets = {}
# permute the matrix for n times
n = b * r
# generate the sig matrix
sigMatrix = sigMatrixGen(input_matrix, n)
# begin and end of band row
begin, end = 0, r
# count the number of band level
count = 0
while end <= sigMatrix.shape[0]:
count += 1
# traverse the column of sig matrix
for colNum in range(sigMatrix.shape[1]):
# generate the hash object, we used md5
hashObj = hashlib.md5()
# calculate the hash value
band = str(sigMatrix[begin: begin + r, colNum]) + str(count)
hashObj.update(band.encode())
# use hash value as bucket tag
tag = hashObj.hexdigest()
# update the dictionary
if tag not in hashBuckets:
hashBuckets[tag] = [colNum]
elif colNum not in hashBuckets[tag]:
hashBuckets[tag].append(colNum)
begin += r
end += r
# return a dictionary
print('\nhash result:')
print(hashBuckets)
print()
return hashBuckets
import numpy as np
mat = np.array([[1, 0, 1, 1, 0], [0, 0, 0, 1, 1], [0, 1, 0, 0, 0], [1, 0, 1, 0, 1], [0, 0, 0, 0, 1], [1, 1, 1, 0, 0], [1, 0, 0, 1, 0]])
print("input:")
print(mat)
minHash(mat, 2, 2)
def nn_search(dataSet, query):
"""
:param dataSet: 2-dimension array
:param query: 1-dimension array
:return: the data columns in data set that are similarity with query
"""
result = set()
input_matrix = np.array(dataSet).T.tolist()
input_matrix.append(query)
input_matrix = np.array(input_matrix).T
print('\ninput_matrix:')
print(input_matrix)
print()
hashBucket = minHash(input_matrix, 2, 2)
queryCol = input_matrix.shape[1] - 1
for key in hashBucket:
if queryCol in hashBucket[key]:
for i in hashBucket[key]:
result.add(i)
result.remove(queryCol)
print('\nresult:')
print(result)
print()
return result
query = [i for i in mat[:, 0]]
query[0] = 1 if query[0] == 0 else 0
print(mat[:, 0])
print(query)
nn_search(mat, query)
nn_search(mat, mat[:, 3])
将桶设置为一般的hash 函数,比如说md5,sha256 等等。
这个时候记录列号,我们把hash 值作为我们字典的键,把列号作为值来计算。
一个字典里面如果,一个键对应的元素是大于两个的,则认为找到了相似的样本。