一种基于门的槽位&意图联合模型¶
2018-08-23
NLP, Slot Filling, Intent Prediction
在对话系统中,Spoken language understanding(语言理解)很重要。其主要完成以下两个关键任务:
- 理解说话人的意图 -- 意图检测(Intent Detection)
- 从句子中提取语义成分 -- 槽位填充(Slot Filling)
可以把意图检测看作一个分类问题,把槽位填充看作一个序列标注问题。
基于Attention的RNN模型在联合意图识别(ID)和槽位填充(SF)已经取得了不错的效果,然而ID和SF的attention权重是独立。
出于槽位跟意图一般都有着很强的相关性,作者提出 slot gate 结构,其关注于学习 intent和slot attention向量之间的关系,通过全局优化获得更好的semantic frame。
以看电影意图为例:
Query: 给 / 我 / 订 / 一张 / 今晚 / 8点 / 的 / 《 / 大圣归来 / 》/ 电影票 / 。
Slots: O / O / O / B-count / B-time / I-time / O / O / B-moive / O / O / O
Intent: book_moive

基于Attention的RNN¶
使用常规的双向LSTM对每个输入进行编码,编码方式为将前向与后向的隐层状态进行拼接:
$$h_i=[\overset{\rightarrow }{h_i}, \overset{\leftarrow }{h_i}]$$Slot Filling
对于槽位填充模块,通过对每个隐层单元学习其对当前隐层单元的权重$\alpha _{i,j}^{S}$,经过加权求和得到每个时刻的槽位上下文表示向量$c_i^S$ , 其中槽位上下文表示为:
$$c_i^S=\sum _{j=i}^{T} \alpha_{i,j}^Sh_j,$$槽位注意力权重为:
$$\alpha_{i, j}^{S}=\frac {exp(e_{i,j})}{\sum _{k=1}^{T}exp(e_{i,k})}$$$$e_{i,k}=\sigma (W_{he}^{S}h_k)$$这里$\sigma$为激活函数,$W_he^S$是一个前向网络的$W$矩阵,由此得出槽位填充标签:
$$y_i^S=softmax(W_{hy}^S(h_i+c_i^S))$$其中$y_i^S$是输入的第i个词的槽位标签,$W_{hy}^S$是权重矩阵.
Intent
意图的上下文表示$c^I$可以参照$c^S$的方式得出,意图识别的部分只用到双向LSTM最后隐层的状态:
$$y_I=softmax(W_{hy}^I(h_T+c^I))$$门逻辑¶
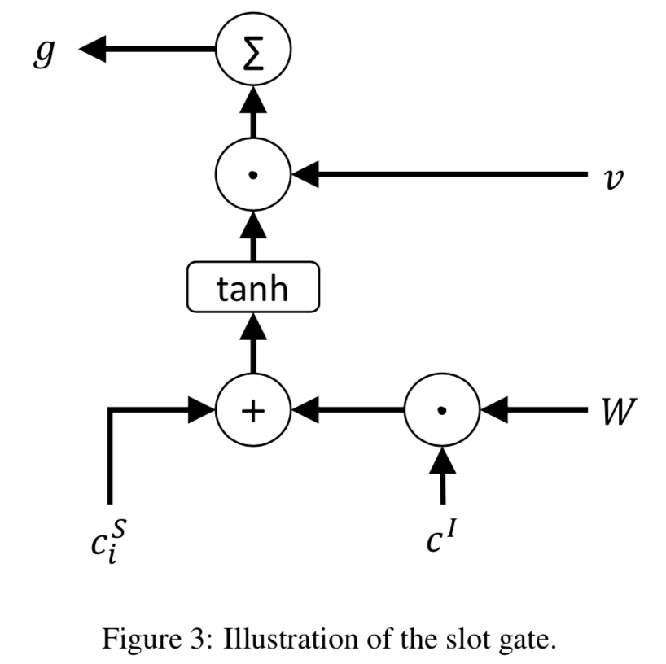
这篇文章提出一个门逻辑,利用 intent context vector 来提升 slot filling 的预测能力。
$$g=\sum v\cdot tanh(c_i^S+W\cdot c^I)$$其中 $v$ 和 $W$ 是trainable 的向量与矩阵,$g$ 可以看作是上下文向量($c_i^S$ 和 $c^I$)的一个加权特征,于是有:
$$y_i^S=softmax(W_{hy}^S(h_i+ c_i^S\cdot g))$$$g$ 越大的部分,说明输入中的这部分,槽位的上下文与意图上下文都有较高的注意力,也推测这部分意图与槽位关联更紧密,该部分的 context vector对结果预测更重要。
为了对照带注意力的门机制,还提出了一种只带意图注意力的简化方案(Intent Only Model, 见Figure2(b))
那么上边的两个公式改写为:
$$g=\sum v\cdot tanh(h_i+W\cdot c^I)$$$$y_i^S=softmax(W_{hy}^S(h_i+ h_i\cdot g))$$联合优化目标函数¶
使用条件概率对槽位填充与意图识别联合建模:
$$ p(y^S, y^I|\mathbf{x})\\ = p(y^I|\mathbf{x})\prod _{t=1}^T p(y_t^S|\mathbf{x}) \\ = p(y^I|x_1,\dots,x_T) \prod _{t=1}^Tp(y_t^S|x_1,\dots,x_T) $$实验结果¶
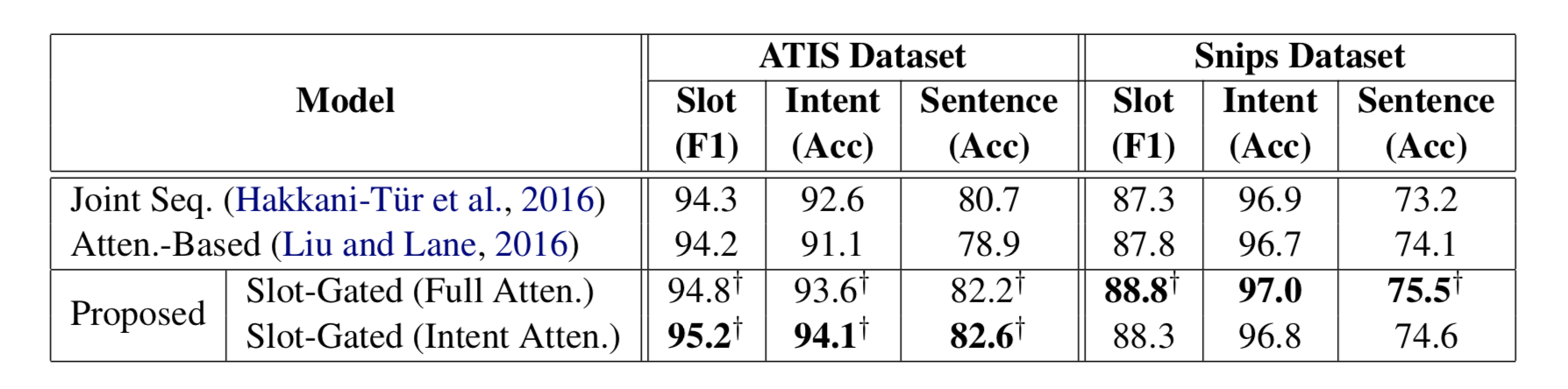
可以看到文中提出的Full Atten. 与Intent Atten. 两个版本在不同数据集中也有不同的表现。
在实际实践中也有类似的结论,在数据简单,数据样本不多的情况下,Intent Atten. 版本表现会略好一些,
建议在实际应用过程中两种方法都尝试,挑选更适合当前场景的版本。