从PageRank到TextRank¶
2018-08-13
keyword, PageRank, TextRank
TextRank是常用的关键词提取与抽取工摘要技术,它并不是一个完全创新的方法,可以说是由PageRank从 SE(IR) 领域“移植”到 NLP。
PageRank¶
PageRank是Google创始人拉里·佩奇和谢尔盖·布林于1998年构建早期的搜索系统原型时提出的链接分析算法。
其提出主要解决的一个问题是通过超链,挖掘潜在的信息,以提高搜索引擎的结果质量。直观地,一个页面被越多的页面所指向,那么这个页面就越重要;同时,重要度也具有传递性,影响相关的其他页面。
其本质是一个图(有向)算法,把每个网页看作节点,把网页(节点)里导向到其他站点的链接看作这个节点的出边,这样,自然地把其它网页(节点)里指向这个网页的链接看作这个节点的入边,每个节点出边的权重值表示其重要度。

PageRank的卡通概念图,图中笑脸的大小与指向该笑脸的其他笑脸的数目成正比.
算法¶
这个方程式引入了随机浏览者(random surfer)的概念,即假设某人在浏览器中随机打开某些页面并点击了某些链接。为了便于理解,这里假设上网者不断点击网页上的链接直到进入一个没有外部链接的网页,此时他会随机浏览其他的网页(可以与之前的网页无关)。
为了处理那些“没有外部链接的页面”(这些页面就像“黑洞”一样吞噬掉用户继续向下浏览的概率)所带来的问题,我们假设:这类页面链接到集合中所有的网页(不管它们是否相关),使得这类网页的PR值将被所有网页均分。对于这种残差概率(residual probability),我们引入阻尼系数 $d$(damping factor),并声明 $d=0.85$,其意义是:任意时刻,用户访问到某页面后继续访问下一个页面的概率,相对应的 $1-d=0.15$ 则是用户停止点击,随机浏览新网页的概率。 $d$ 的大小由一般上网者使用浏览器书签功能的频率的平均值估算得到。
对于某个页面i,其对应PR值大小的计算公式如下:
$$PR(p_i)=\frac{1-d}{N}+d \sum_{p_j\in M(p_i)}\frac{PR(p_j)}{L(p_j)}$$这里, $p_{1},p_{2},...,p_{N}$是目标页面 $p_{i}$, $M(p_{i})$是链入 $p_{i}$页面的集合, $L(p_{j})$是页面$p_{j}$链出页面的数量,而$N$是集合中所有页面的数量。
* 需要注意的是,在Sergey Brin和Lawrence Page的1998年原版论文中给每一个页面设定的最小值是 $1-d$,而不是这里的$(1-d)/N$,这将导致集合中所有网页的PR值之和为$N$(N为集合中网页的数目)而非所期待的$1$。
集合中所有页面的PR值可以由一个特殊的邻接矩阵的特征向量表示。这个特征向量$R$为:
同时,$R$也是下面的方程组的解:
这里的邻接函数(adjacency function)$l(p_{i},p_{j})$ 代表“从页面j指向页面i的链接数”与“页面j中含有的外部链接总数”的比值 如果$p_{j}$不链向$p_{i}$,则前面提到的“从页面j指向页面i的链接数”为零。将情况一般化:对于特定的j,应有:
$$ \sum _{i=1}^N l(p_i, p_j) = 1 $$import os
import sys
import math
import numpy
import pandas
# Generalized matrix operations:
def __extractNodes(matrix):
nodes = set()
for colKey in matrix:
nodes.add(colKey)
for rowKey in matrix.T:
nodes.add(rowKey)
return nodes
def __makeSquare(matrix, keys, default=0.0):
matrix = matrix.copy()
def insertMissingColumns(matrix):
for key in keys:
if not key in matrix:
matrix[key] = pandas.Series(default, index=matrix.index)
return matrix
matrix = insertMissingColumns(matrix) # insert missing columns
matrix = insertMissingColumns(matrix.T).T # insert missing rows
return matrix.fillna(default)
def __ensureRowsPositive(matrix):
matrix = matrix.T
for colKey in matrix:
if matrix[colKey].sum() == 0.0:
matrix[colKey] = pandas.Series(numpy.ones(len(matrix[colKey])), index=matrix.index)
return matrix.T
def __normalizeRows(matrix):
return matrix.div(matrix.sum(axis=1), axis=0)
def __euclideanNorm(series):
return math.sqrt(series.dot(series))
# PageRank specific functionality:
def __startState(nodes):
if len(nodes) == 0: raise ValueError("There must be at least one node.")
startProb = 1.0 / float(len(nodes))
return pandas.Series({node : startProb for node in nodes})
def __integrateRandomSurfer(nodes, transitionProbabilities, rsp):
alpha = 1.0 / float(len(nodes)) * rsp
return transitionProbabilities.copy().multiply(1.0 - rsp) + alpha
def powerIteration(transitionWeights, rsp=0.15, epsilon=0.00001, maxIterations=1000):
# Clerical work:
transitionWeights = pandas.DataFrame(transitionWeights)
nodes = __extractNodes(transitionWeights)
transitionWeights = __makeSquare(transitionWeights, nodes, default=0.0)
transitionWeights = __ensureRowsPositive(transitionWeights)
# Setup:
state = __startState(nodes)
transitionProbabilities = __normalizeRows(transitionWeights)
transitionProbabilities = __integrateRandomSurfer(nodes, transitionProbabilities, rsp)
# Power iteration:
for iteration in range(maxIterations):
oldState = state.copy()
state = state.dot(transitionProbabilities)
delta = state - oldState
if __euclideanNorm(delta) < epsilon:
break
return state
import collections
vertex_list = ['a', 'b', 'c', 'd']
link_list = {'a': ['b', 'c'], 'b': ['a'], 'c': ['a', 'd']}
transitionWeights = {}
for i in vertex_list:
for k in link_list.get(i, []):
if i not in transitionWeights:
transitionWeights[i] = collections.Counter()
transitionWeights[i][k] += 1
print(transitionWeights)
powerIteration(transitionWeights, rsp=0.15, epsilon=0.00001, maxIterations=1000)
Map-reduce计算Page Rank¶
上面的演算过程,采用矩阵相乘,不断迭代,直到迭代前后概率分布向量的值变化不大,一般迭代到30次以上就收敛了。
真的的web结构的转移矩阵非常大,目前的网页数量已经超过100亿,转移矩阵是100亿*100亿的矩阵,直接按矩阵乘法的计算方法不可行,需要借助Map-Reduce的计算方式来解决。
实际上,google发明Map-Reduce最初就是为了分布式计算大规模网页的pagerank.
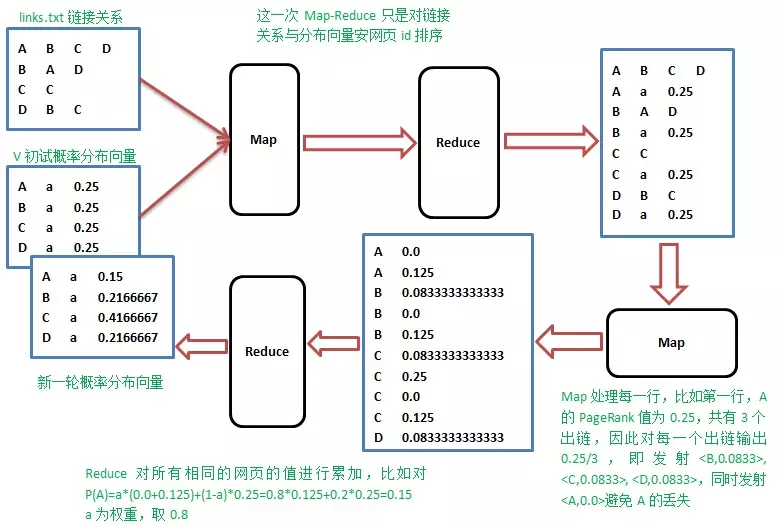
- Map阶段
Map操作的每一行,对所有出链发射当前网页概率值的1/k,k是当前网页的出链数,比如对第一行输出
B 1/3*1/4
C 1/3*1/4
D 1/3*1/4
- Reduce阶段
Reduce操作收集网页id相同的值,累加并按权重计算,$p_j=a(p_1+p_2+...+P_m)+(1-a)\frac {1}{n}$,其中$m$是指向网页$j$的网页个数,$n$是所有网页数。
流程如下:
缺陷¶
PageRank算法的主要缺点在于旧的页面的排名往往会比新页面高。
因为即使是质量很高的新页面也往往不会有很多外链,除非它是某个已经存在站点的子站点。
这也是PageRank需要多项算法结合以保证其结果的准确性的原因。
例如,PageRank似乎偏好于维基百科页面,在条目名称的搜索结果中,维基百科页面经常在大多数页面甚至所有页面之前,此现象的原因则是维基百科内部网页中存在大量的内链,同时亦有很多站点链入维基百科。
TextRank¶
理解了PageRank的原理后,TankRank其实就是在NLP下的应用。
与之不同的是,PageRank中,网页(节点)与网页(节点)之间是有向无权图的结构,在TextRank中通常会是有向(或无向)带权图。(*注意: 无向也可以看作为双向)
还有就是公式多了$w$调权部分:
$$ WS(V_i)=(1-d)+d*\sum _{V_j\in In(V_i)} \frac{w_{ji}}{\sum _{V_k\in Out(V_j)} w_{jk}}WS(V_j) $$文本转图思路¶
将图算法应用到文本处理通常经过以下几个步骤:
- 针对不同的任务,确定适宜的文本单元,并将其以节点的形式加入到图中;
- 确定文本单元之间的关系,并将其关系以边的形式表示在图中,这里的边可以是有向/无向的,可以是带权/不带权的;
- 迭代基于图的Ranking算法,直至收敛;
- 基于节点得分对结果排序、选择。
关键词提取¶
在提取关键词的场景,文本单元自然是词的粒度。
套到上边的算法过程就是:
- 先做分词以及词性分析,词性过滤(一般助词什么的可以过滤掉);
- 根据N-gram词的共现关系,确定词(节点)的边,构建无向不带权的图,并将节点的值初始化为1;
- 迭代TextRank算法直至收敛;
- 基于节点得分对结果排序、选择Top K个作为关键词,对于相邻的关键词,可以尝试合并。
下图为一个对摘要进行关键词提取的例子
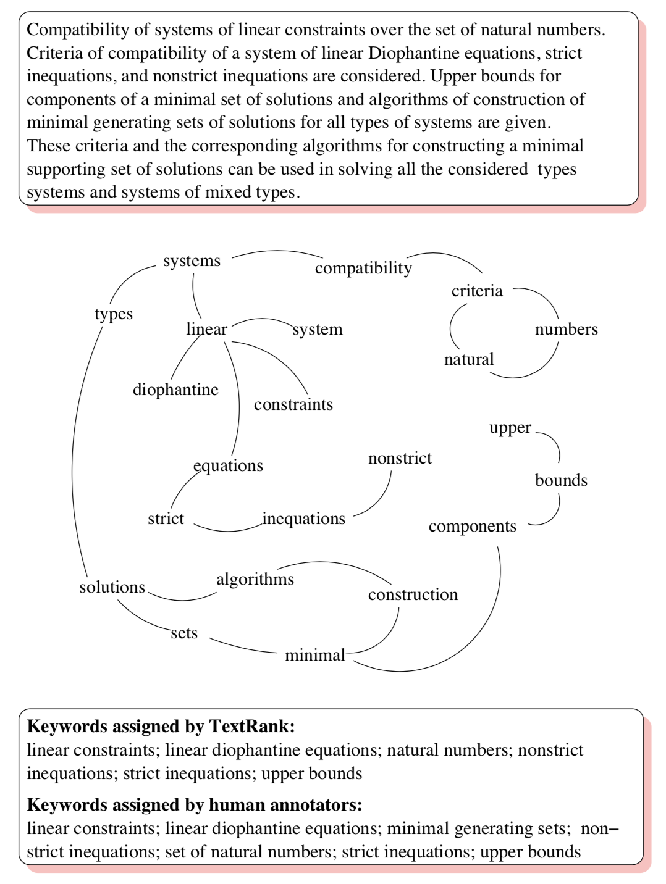
关键句抽取¶
相似的,以句子为粒度,可以实现对文章或文章片段做关键句抽取:
- 以句子为粒度切句;
- 句子与句子间两两关联,并计算两两之间的相似度作为边的权值,构建无向带权图;
- 迭代TextRank算法,直至收敛
- 基于节点得分对结果排序、选择Top K个以原文序排列后作为摘要结果。
下面以jieba库为例看看实际的关键词提取效果如何:
import sys
sys.path.insert(0, '/Users/ansvver/anaconda3/envs/tf_models/lib/python3.6/site-packages/jieba/')
import jieba.analyse
sentence = """今年夏天火箭队为豪斯提供了一份3年1110万美元的合同,他用自己的表现为自己赢得了一份不错的合同。
上赛季他的表现颇具争议,常规赛表现猛如虎,但是一到了季后赛就不行了,以至于最后直接跌出了轮换阵容,遭到了德安东尼的弃用,
我们只知道豪斯被弃用了,但是并不清楚原因在哪里。
火箭队总经理在最新一期的Rocketscast节目中谈到了豪斯,他表示豪斯是球队非常重要的球员,他在火箭队被视为球队的核心成员,
莫雷表示:“我们觉得他可以做到。去年大部分赛季他都是这样。” 莫雷补充说:“他的第一次脚趾受伤进入季后赛并不完美,
因为他的脚趾受伤限制了这名26岁的球员在上个季后赛的上场时间和表现。”“但这只是上赛季他帮助我们的漫长过程中的一小部分。”
作为土生土长的休斯敦人,身高6英尺7英寸的豪斯在2018-19赛季场均25.1分钟的上场时间里拿下9.4分3.6个篮板,
这是他在火箭队的第一个赛季的表现。豪斯的运动能力、防守的韧劲和远距离的柔和手感(三分球命中率41.6%),
使他很快成为主教练德安东尼轮换阵容中的一员。"""
jieba.analyse.textrank(sentence, topK=5, withWeight=False, allowPOS=('ns', 'n', 'vn', 'v'))
总结¶
TextRank是一种基于图的关键词/句提取算法,能够无监督地学习到文本的蕴涵信息,而不需要大量的标注语料或领域知识。
通过调整节点的连接关系以及$w$权重的计算策略(tfidf/wmd/cosine),也可以对特定的语料进行优化。
同时针对不同的应用场景,根据灵活转变都可以实现提取关键部分的功能。
但也存在一些不足,算法考虑的特征较少,实际效果还得根据实际的应用场景进行选择,或将其结果作为一个特征进行再加工。