bi-LSTM + CRF 序列标注¶
2018-02-15
NLP, LSTM, NER, CNN
本文将基于几篇近年来 BiLSTM 与 CRF 做 NER 的论文,结合具体的 Tensorflow 代码,理解常见的深度学习序列标注方法。
序列标注¶
序列标注问题是自然语言处理中的基本问题之一,在深度学习火起来之前,常见的序列标注问题的解决方案都是借助于HMM模型,最大熵模型,CRF模型。尤其是CRF,是解决序列标注问题的主流方法。
随着深度学习的发展,RNN在序列标注问题中取得了巨大的成果。而且深度学习中的 end-to-end,也让序列标注问题变得更简单了。
序列标注问题包括自然语言处理中的分词,词性标注,命名实体识别,关键词抽取,词义角色标注等等。我们只要在做序列标注时给定特定的标签集合,就可以进行序列标注。
bi-LSTM + CRF¶
论文链接:Bidirectional LSTM-CRF Models for Sequence Tagging
经典的 BiLSTM-CRF 模型结构不复杂,双向的 LSTM 可以更好地刻画同一时刻上下文(前文与后文)对当前状态的影响,而 CRF 则在句子级别对 tag 序列进行约束。
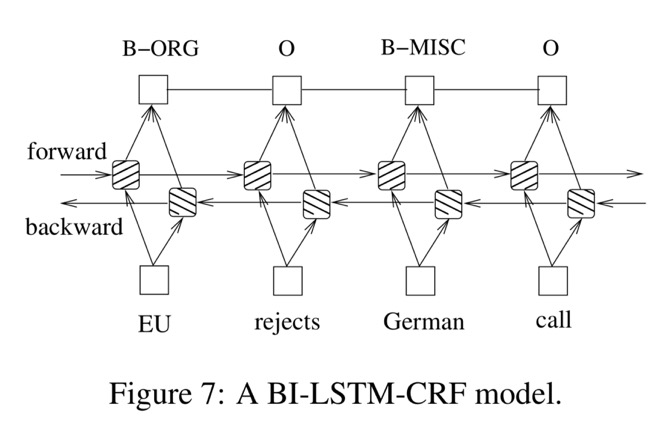
值得注意的是模块的输入可以是 token 的 one-hot 编码或 embedding 或对应的稀疏特征。
最终,在参数
$$\tilde{\theta}=\theta \cup \{[A]_{i,j} \forall i,j\}$$(其中$\theta$ 表示 LSTM 模块的网络参数,$[A]_{i,j}$ 表示Tag从第i个值到第j个值的转移值,转移矩阵由 CRF 算得)下,句子 $[X]_1^T$ 对应标签序列 $[i]_1^T$ 的得分为:
$$s([x]_1^T, [i]_1^T, \tilde{\theta})=\sum _{t=1}^T ([A]_{[i]_{t-1},[i]_t}+[f_{\theta}]_{[i]_t,t})$$模型训练步骤如下:

下面以 token 的 Embedding 作为输入的训练过程代码片断:
# 注意,在以下的 `words` 可用 `dateset.padded_batch` 使之长度相同(不足的以默认值补充)
# Word Embeddings
vocab_words = tf.contrib.lookup.index_table_from_file(
params['words_filepath'], num_oov_buckets=1)
word_ids = vocab_words.lookup(words)
glove = np.load(params['glove'])['embeddings'] # np.array
variable = np.vstack([glove, [[0.]*params['dim']]]) # 注意这里的最后一维是零向量
variable = tf.Variable(variable, dtype=tf.float32, trainable=False)
embeddings = tf.nn.embedding_lookup(variable, word_ids)
embeddings = tf.layers.dropout(embeddings, rate=dropout, training=training) # Embedding 层做 dropout
# BiLSTM
t = tf.transpose(embeddings, perm=[1, 0, 2]) # 转置成以句子序列为主
lstm_cell_fw = tf.contrib.rnn.LSTMBlockFusedCell(params['lstm_size']) # 构建前向rnn
lstm_cell_bw = tf.contrib.rnn.LSTMBlockFusedCell(params['lstm_size'])
lstm_cell_bw = tf.contrib.rnn.TimeReversedFusedRNN(lstm_cell_bw) # 构建反向rnn
output_fw, _ = lstm_cell_fw(t, dtype=tf.float32, sequence_length=nwords)
output_bw, _ = lstm_cell_bw(t, dtype=tf.float32, sequence_length=nwords)
output = tf.concat([output_fw, output_bw], axis=-1)
# [output_fw_1, output_fw_2, ..., output_fw_n, output_bw_1, output_bw_2, ..., output_bw_n]
output = tf.transpose(output, perm=[1, 0, 2]) # 转置回以batch为主
output = tf.layers.dropout(output, rate=dropout, training=training) # BiLSTM 做 dropout
# CRF
logits = tf.layers.dense(output, num_tags) # 全连接层,维度是标签的个数
crf_params = tf.get_variable("crf", [num_tags, num_tags], dtype=tf.float32)
pred_ids, _ = tf.contrib.crf.crf_decode(logits, crf_params, nwords)
Chars LSTM + bi-LSTM + CRF¶
论文链接:Neural Architectures for Named Entity Recognition
与经典的 BiLSTM-CRF 模型结构,在此基础上考虑了字粒度(英文语料中就是字母)的特征,文中提到这么做有以下几个好处:
- 保留语言中词语里的形态
- 解决词性标注、语言模型或依存句法分析中OOV的问题
Chars embeddings 也是由 bi-LSTM 得出,可选择性加入字的原始embedding
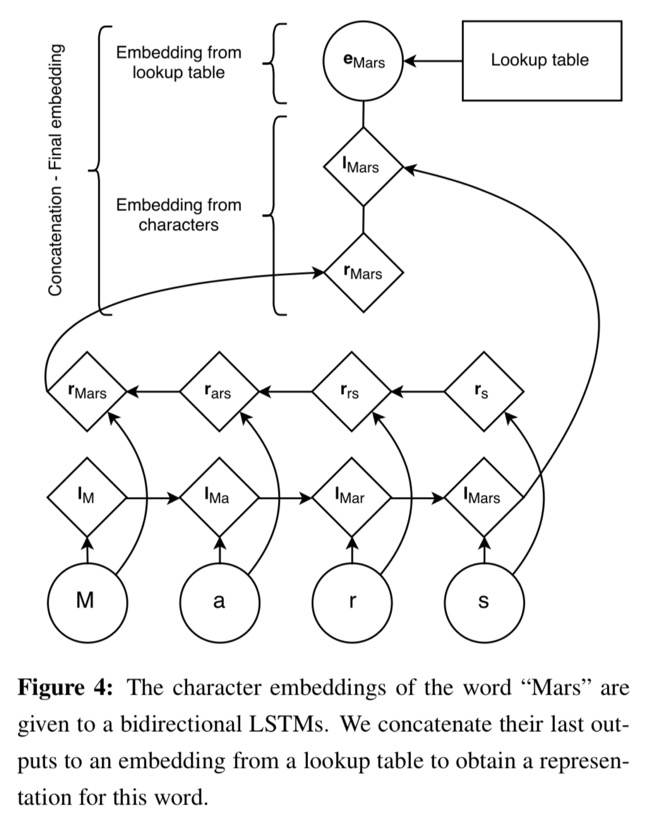
# Char Embeddings
char_ids = vocab_chars.lookup(chars)
variable = tf.get_variable(
'chars_embeddings', [num_chars, params['dim_chars']], tf.float32)
char_embeddings = tf.nn.embedding_lookup(variable, char_ids)
char_embeddings = tf.layers.dropout(char_embeddings, rate=dropout,
training=training)
# Char LSTM
dim_words = tf.shape(char_embeddings)[1]
dim_chars = tf.shape(char_embeddings)[2]
flat = tf.reshape(char_embeddings, [-1, dim_chars, params['dim_chars']])
t = tf.transpose(flat, perm=[1, 0, 2])
lstm_cell_fw = tf.contrib.rnn.LSTMBlockFusedCell(params['char_lstm_size'])
lstm_cell_bw = tf.contrib.rnn.LSTMBlockFusedCell(params['char_lstm_size'])
lstm_cell_bw = tf.contrib.rnn.TimeReversedFusedRNN(lstm_cell_bw)
_, (_, output_fw) = lstm_cell_fw(t, dtype=tf.float32,
sequence_length=tf.reshape(nchars, [-1]))
_, (_, output_bw) = lstm_cell_bw(t, dtype=tf.float32,
sequence_length=tf.reshape(nchars, [-1]))
output = tf.concat([output_fw, output_bw], axis=-1) # 这里可以加入 Embedding from lookup table
char_embeddings = tf.reshape(output, [-1, dim_words, 50])
做完 chars embedding 后与 word embedding 做一个 Concatenate操作后再作为bi-LSTM的输入即可:
# Word Embeddings
word_ids = vocab_words.lookup(words)
glove = np.load(params['glove'])['embeddings'] # np.array
variable = np.vstack([glove, [[0.] * params['dim']]])
variable = tf.Variable(variable, dtype=tf.float32, trainable=False)
word_embeddings = tf.nn.embedding_lookup(variable, word_ids)
# Concatenate Word and Char Embeddings
embeddings = tf.concat([word_embeddings, char_embeddings], axis=-1)
embeddings = tf.layers.dropout(embeddings, rate=dropout, training=training)
# LSTM
t = tf.transpose(embeddings, perm=[1, 0, 2]) # Need time-major
lstm_cell_fw = tf.contrib.rnn.LSTMBlockFusedCell(params['lstm_size'])
lstm_cell_bw = tf.contrib.rnn.LSTMBlockFusedCell(params['lstm_size'])
lstm_cell_bw = tf.contrib.rnn.TimeReversedFusedRNN(lstm_cell_bw)
output_fw, _ = lstm_cell_fw(t, dtype=tf.float32, sequence_length=nwords)
output_bw, _ = lstm_cell_bw(t, dtype=tf.float32, sequence_length=nwords)
output = tf.concat([output_fw, output_bw], axis=-1)
output = tf.transpose(output, perm=[1, 0, 2])
output = tf.layers.dropout(output, rate=dropout, training=training)
# CRF
logits = tf.layers.dense(output, num_tags)
crf_params = tf.get_variable("crf", [num_tags, num_tags], dtype=tf.float32)
pred_ids, _ = tf.contrib.crf.crf_decode(logits, crf_params, nwords)
Chars CNN + bi-LSTM + CRF¶
论文链接:End-to-end Sequence Labeling via Bi-directional LSTM-CNNs-CRF
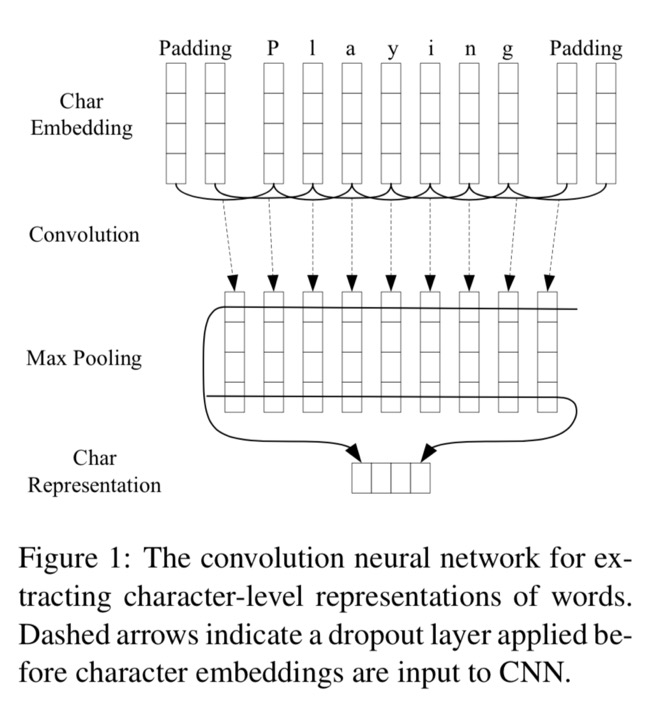
这篇文章与前一篇是同一时期出的,思想大致相同,只不过前一篇用的是bi-LSTM做字符级的Embedding,而这篇采用的则是CNN的做法。
文章提到CNN可以有效地捕获单词形态上的特征,目的与上一篇相像。
CNN的结构如下:
def masked_conv1d_and_max(t, weights, filters, kernel_size):
"""Applies 1d convolution and a masked max-pooling
Parameters
----------
t : tf.Tensor
A tensor with at least 3 dimensions [d1, d2, ..., dn-1, dn]
weights : tf.Tensor of tf.bool
A Tensor of shape [d1, d2, dn-1]
filters : int
number of filters
kernel_size : int
kernel size for the temporal convolution
Returns
-------
tf.Tensor
A tensor of shape [d1, d2, dn-1, filters]
"""
# Get shape and parameters
shape = tf.shape(t)
ndims = t.shape.ndims
dim1 = reduce(lambda x, y: x*y, [shape[i] for i in range(ndims - 2)])
dim2 = shape[-2]
dim3 = t.shape[-1]
# Reshape weights
weights = tf.reshape(weights, shape=[dim1, dim2, 1]) # 可以看作一个mask,由单词长度的tf.sequence_mask操作得到
weights = tf.to_float(weights)
# Reshape input and apply weights
flat_shape = [dim1, dim2, dim3]
t = tf.reshape(t, shape=flat_shape)
t *= weights # <pad> 填充部分的embedding会置0
# Apply convolution
t_conv = tf.layers.conv1d(t, filters, kernel_size, padding='same') # (dim1, dim2, filters)
t_conv *= weights # <pad> 填充部分的embedding会置0
# Reduce max -- set to zero if all padded
# 右边是:(dim1, dim2, 1) * (dim1, 1, filters)
# 总的是:(dim1, dim2, filters) + (dim1, dim2, filters)
t_conv += (1. - weights) * tf.reduce_min(t_conv, axis=-2, keepdims=True) # 这个是将训练出来的所有<pad>的embedding中每列的min值组合起来做为结果中<pad>的embedding
t_max = tf.reduce_max(t_conv, axis=-2) # maxpooling, (dim1, 1, filters)
# Reshape the output
final_shape = [shape[i] for i in range(ndims-2)] + [filters] # [d1, d2, dn-1, filters]
t_max = tf.reshape(t_max, shape=final_shape)
return t_max
完整的训练过程如下:
char_ids = vocab_chars
# Char Embeddingslookup(chars)
variable = tf.get_variable(
'chars_embeddings', [num_chars + 1, params['dim_chars']], tf.float32)
char_embeddings = tf.nn.embedding_lookup(variable, char_ids) # trainable = True
char_embeddings = tf.layers.dropout(char_embeddings, rate=dropout,
training=training)
# Char 1d convolution
weights = tf.sequence_mask(nchars) # 做一个mask
char_embeddings = masked_conv1d_and_max(
char_embeddings, weights, params['filters'], params['kernel_size'])
# Word Embeddings
word_ids = vocab_words.lookup(words)
glove = np.load(params['glove'])['embeddings'] # np.array
variable = np.vstack([glove, [[0.] * params['dim']]])
variable = tf.Variable(variable, dtype=tf.float32, trainable=False)
word_embeddings = tf.nn.embedding_lookup(variable, word_ids)
# Concatenate Word and Char Embeddings
embeddings = tf.concat([word_embeddings, char_embeddings], axis=-1)
embeddings = tf.layers.dropout(embeddings, rate=dropout, training=training)
# LSTM
t = tf.transpose(embeddings, perm=[1, 0, 2]) # Need time-major
lstm_cell_fw = tf.contrib.rnn.LSTMBlockFusedCell(params['lstm_size'])
lstm_cell_bw = tf.contrib.rnn.LSTMBlockFusedCell(params['lstm_size'])
lstm_cell_bw = tf.contrib.rnn.TimeReversedFusedRNN(lstm_cell_bw)
output_fw, _ = lstm_cell_fw(t, dtype=tf.float32, sequence_length=nwords)
output_bw, _ = lstm_cell_bw(t, dtype=tf.float32, sequence_length=nwords)
output = tf.concat([output_fw, output_bw], axis=-1)
output = tf.transpose(output, perm=[1, 0, 2])
output = tf.layers.dropout(output, rate=dropout, training=training)
# CRF
logits = tf.layers.dense(output, num_tags)
crf_params = tf.get_variable("crf", [num_tags, num_tags], dtype=tf.float32)
pred_ids, _ = tf.contrib.crf.crf_decode(logits, crf_params, nwords)
总结¶
本文介绍了基于bi-LSTM + CRF序列标注的经典结构与基于此的一些变种。
其变种也主要是对字符级特征的提取,个人感觉对英文类的语言帮助会更大(中文一个词语的字符一般较少),另外是能解决部分OOV的问题。
三种方法的在 CoNLL2003 shared task 的表现上,后两个加入chars embedding的方法会有一定的提升,但提升并没有很明显,具体结果可见:guillaumegenthial/tf_ner
最后附上 guillaumegenthial/tf_ner 对这三个模型选用的建议:
Also, considering the complexity of the models and the relatively small gap in performance (0.6 F1), using the lstm_crf model is probably a safe bet for most of the concrete applications.
参考文献:
- Bidirectional LSTM-CRF Models for Sequence Tagging by Huang, Xu and Yu
- Neural Architectures for Named Entity Recognition by Lample et al.
- End-to-end Sequence Labeling via Bi-directional LSTM-CNNs-CRF by Ma et Hovy
- guillaumegenthial/tf_ner by Guillaume Genthial