BiMPM:一个句子匹配模型¶
2018-03-21
BiMPM, PyTorch
自然语言句子匹配(Natural language sentence matching, NLSM) 技术的主要目的是比较两个句子并找出它们之间的关系。
基于此,可应用于多种场景任务下,比如在自然语言推理中,可以用来推测两个句子是否存在推断与前提的关系;在qa对问答场景中,可以用来判断问句与答案之前的匹配关系,以及对多个答案进行排序;在搜索场景中,可以用来匹配query与文档片段的对应关系等等。
随着神经网络的发展,对NLSM所提出的模型大致可以分为两大类:
- 第一类叫孪生网络(Siamese Networks),通过构建相同的网络结构对输入的句子对进行编码(如
CNN或RNN),进而单独对得到的两个空间向量进行匹配度量; - 第二类个人称之为交互匹配网络(Matching-aggregation Networks),这类网络通常以字符级或上下文对两句子做匹配,然后对匹配的结果使用网络结构(如
CNN或LSTM)进行融合,最后对编码出的一个向量做决策。
第一类的优点是相同网络参数共享使得网络的规模更小和便于训练,得出的(两个)向量可以直接用于可视化、其他聚类分类等;缺点是两个句子间在encode的阶段是相互独立(无信息交互),这导致训练过程可以会丢失某些重要的信息。
第二类模型通过在训练过程中加入两个句子间的“匹配交互”,这使得效果较第一类能更好一些。
BIMPM 属于第二类模型。该论文提出一种双边多视角匹配(Bilateral Multi-Perspective Matching, BiMPM)模型用于句子匹配。
论文通过大量实验表明BiMPM模型在不同类型的句子匹配数据集上都达到了比较好的效果,包括在Quora数据集上的释义识别(paraphrase identification)任务, 在SNLI 数据集上的自然语言推理(natural language inference)任务,以及在TREC-QA和 WikiQA数据集上的答案句子选择(answer sentence selection)任务,从而说明BiMPM模型的实用性。
BiMPM¶
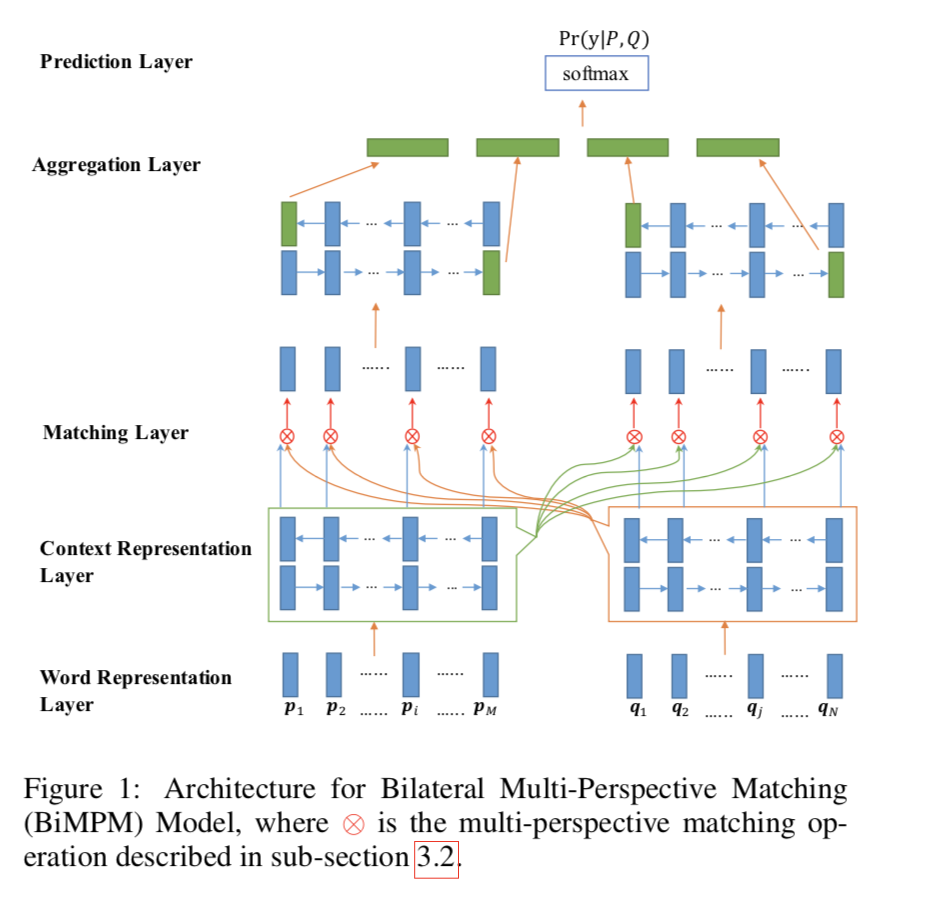
算法流程描述:
- 给定两个句子P与Q,使用双向LSTM对它们分别进行编码;
- 对这两个编码后的句子从 P → Q 以及 P ← Q 两个过程进行匹配,以 P → Q 过程为例(P ← Q 过程相似),Q的每个time-step都对P的所有time-steps,在多个视角下进行匹配;
- 使用另一个BiLSTM来聚合匹配的结果到一个固定长度的匹配向量里;
- 最后通过一个全链接层完成最终的匹配结果映射。
模型结果概图如下:
PyTorch 模型初始化如下:
class BIMPM(nn.Module):
def __init__(self, args, data):
super(BIMPM, self).__init__()
self.args = args
self.d = self.args.word_dim + int(self.args.use_char_emb) * self.args.char_hidden_size
self.l = self.args.num_perspective
# ----- Word Representation Layer -----
self.char_emb = nn.Embedding(args.char_vocab_size, args.char_dim, padding_idx=0)
self.word_emb = nn.Embedding(args.word_vocab_size, args.word_dim)
# initialize word embedding with GloVe
self.word_emb.weight.data.copy_(data.TEXT.vocab.vectors)
# no fine-tuning for word vectors
self.word_emb.weight.requires_grad = False # 这里词向量直接使用训练好的向量模型,不再重新训练
self.char_LSTM = nn.LSTM(
input_size=self.args.char_dim,
hidden_size=self.args.char_hidden_size,
num_layers=1,
bidirectional=False,
batch_first=True) # 使用一个单向LSTM训练字向量
# ----- Context Representation Layer -----
self.context_LSTM = nn.LSTM(
input_size=self.d,
hidden_size=self.args.hidden_size,
num_layers=1,
bidirectional=True,
batch_first=True
) # 使用双向LSTM训练上下文表达层
# ----- Matching Layer -----
for i in range(1, 9):
setattr(self, f'mp_w{i}',
nn.Parameter(torch.rand(self.l, self.args.hidden_size))) # 存放8个Matching结果
# ----- Aggregation Layer -----
self.aggregation_LSTM = nn.LSTM(
input_size=self.l * 8,
hidden_size=self.args.hidden_size,
num_layers=1,
bidirectional=True,
batch_first=True
) # 同样使用双向LSTM训练融合层
# ----- Prediction Layer -----
self.pred_fc1 = nn.Linear(self.args.hidden_size * 4, self.args.hidden_size * 2)
self.pred_fc2 = nn.Linear(self.args.hidden_size * 2, self.args.class_size) # 最后是接两个全连接层
self.reset_parameters()
def dropout(self, v):
return F.dropout(v, p=self.args.dropout, training=self.training)
下面将根据模型的各个layer进行分析介绍。
1. Word Representation Layer¶
输入编码层:使用LSTM,对字向量进行编码,然后与词向量拼接在一起,最后保持向量个数与对应的句子序列长度相等。
# (batch, seq_len) -> (batch, seq_len, word_dim)
p = self.word_emb(kwargs['p']) # p for premise, 当然不同任务可有不同理解
h = self.word_emb(kwargs['h']) # h for hypothesis
if self.args.use_char_emb:
# (batch, seq_len, max_word_len) -> (batch * seq_len, max_word_len)
seq_len_p = kwargs['char_p'].size(1)
seq_len_h = kwargs['char_h'].size(1)
char_p = kwargs['char_p'].view(-1, self.args.max_word_len)
char_h = kwargs['char_h'].view(-1, self.args.max_word_len)
# (batch * seq_len, max_word_len, char_dim)-> (1, batch * seq_len, char_hidden_size)
_, (char_p, _) = self.char_LSTM(self.char_emb(char_p))
_, (char_h, _) = self.char_LSTM(self.char_emb(char_h))
# (batch, seq_len, char_hidden_size)
char_p = char_p.view(-1, seq_len_p, self.args.char_hidden_size)
char_h = char_h.view(-1, seq_len_h, self.args.char_hidden_size)
# (batch, seq_len, word_dim + char_hidden_size)
p = torch.cat([p, char_p], dim=-1)
h = torch.cat([h, char_h], dim=-1)
p = self.dropout(p)
h = self.dropout(h)
2. Context Representation Layer¶
上下文表示层:对上一步得到的编码序列使用BiLSTM使之加入序列上下文信息。
# ----- Context Representation Layer -----
# (batch, seq_len, hidden_size * 2)
con_p, _ = self.context_LSTM(p)
con_h, _ = self.context_LSTM(h)
con_p = self.dropout(con_p)
con_h = self.dropout(con_h)
# (batch, seq_len, hidden_size)
con_p_fw, con_p_bw = torch.split(con_p, self.args.hidden_size, dim=-1)
con_h_fw, con_h_bw = torch.split(con_h, self.args.hidden_size, dim=-1)
3. Matching Layer¶
匹配层:这是此模块的核心层。
其目的是取句子中每一个上下文 embedding (time-step) 与另一句子中所有上下文 embedding (time-step) 作比较。最后输出两个匹配的 embedding。
首先,定义多视角函数
$$m = f_m(v_1, v_2; W)$$其中$f_m$的输入是两个维度为$d$的向量$v1, v2$,输出是一个$l$维的向量$m$, $l$为视角维度,$W$是大小为$l\times d$可训练的参数。具体地,向量$m$的第k个维度
$$m_k=cosine(W_k \circ v_1, W_k \circ v_2)$$其中$\circ$是element-wise乘法(对位相乘), $k \in [1,l]$。
基于$f_m$,采取如下四种匹配策略得到4个匹配向量$m$:
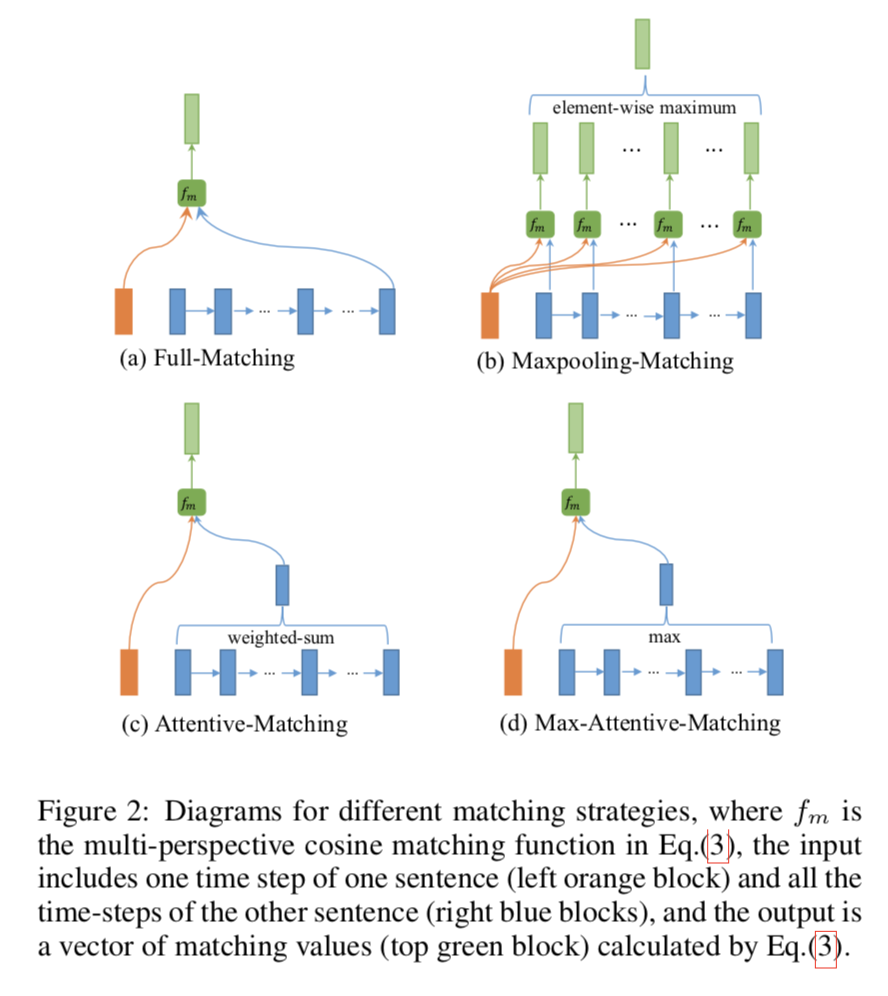
- 全匹配 (Full-Matching):句子$P$的当前时刻的上下文表示层前向隐藏层向量(后向隐藏层向量)与另一个句子Q的上下文表示层的最后一个向量(第一个向量)作为$f_m$输入(因为上下文表示层是双向LSTM)。
# 1. Full-Matching
# (batch, seq_len, hidden_size), (batch, hidden_size)
# -> (batch, seq_len, l)
mv_p_full_fw = mp_matching_func(con_p_fw, con_h_fw[:, -1, :], self.mp_w1)
mv_p_full_bw = mp_matching_func(con_p_bw, con_h_bw[:, 0, :], self.mp_w2)
mv_h_full_fw = mp_matching_func(con_h_fw, con_p_fw[:, -1, :], self.mp_w1)
mv_h_full_bw = mp_matching_func(con_h_bw, con_p_bw[:, 0, :], self.mp_w2)
def mp_matching_func(v1, v2, w):
"""
:param v1: (batch, seq_len, hidden_size)
:param v2: (batch, seq_len, hidden_size) or (batch, hidden_size)
:param w: (l, hidden_size)
:return: (batch, l)
"""
seq_len = v1.size(1)
# (1, 1, hidden_size, l)
w = w.transpose(1, 0).unsqueeze(0).unsqueeze(0)
# (batch, seq_len, hidden_size, l)
v1 = w * torch.stack([v1] * self.l, dim=3)
if len(v2.size()) == 3:
v2 = w * torch.stack([v2] * self.l, dim=3)
else:
v2 = w * torch.stack([torch.stack([v2] * seq_len, dim=1)] * self.l, dim=3)
m = F.cosine_similarity(v1, v2, dim=2)
return m
- 最大池化匹配 (Maxpooling-Matching):句子$P$的当前时刻的上下文表示层向量与另一个句子Q的上下文表示层的所有向量分别作为$f_m$输入,然后对所有输出进行maxpooling。
# 2. Maxpooling-Matching
# (batch, seq_len1, seq_len2, l)
mv_max_fw = mp_matching_func_pairwise(con_p_fw, con_h_fw, self.mp_w3)
mv_max_bw = mp_matching_func_pairwise(con_p_bw, con_h_bw, self.mp_w4)
# (batch, seq_len, l)
mv_p_max_fw, _ = mv_max_fw.max(dim=2)
mv_p_max_bw, _ = mv_max_bw.max(dim=2)
mv_h_max_fw, _ = mv_max_fw.max(dim=1)
mv_h_max_bw, _ = mv_max_bw.max(dim=1)
def div_with_small_value(n, d, eps=1e-8):
# too small values are replaced by 1e-8 to prevent it from exploding.
d = d * (d > eps).float() + eps * (d <= eps).float()
return n / d
def mp_matching_func_pairwise(v1, v2, w):
"""
:param v1: (batch, seq_len1, hidden_size)
:param v2: (batch, seq_len2, hidden_size)
:param w: (l, hidden_size)
:return: (batch, l, seq_len1, seq_len2)
"""
# (1, l, 1, hidden_size)
w = w.unsqueeze(0).unsqueeze(2)
# (batch, l, seq_len, hidden_size)
v1, v2 = w * torch.stack([v1] * self.l, dim=1), w * torch.stack([v2] * self.l, dim=1)
# (batch, l, seq_len, hidden_size->1)
v1_norm = v1.norm(p=2, dim=3, keepdim=True)
v2_norm = v2.norm(p=2, dim=3, keepdim=True)
# (batch, l, seq_len1, seq_len2)
n = torch.matmul(v1, v2.transpose(2, 3))
d = v1_norm * v2_norm.transpose(2, 3)
# (batch, seq_len1, seq_len2, l)
m = div_with_small_value(n, d).permute(0, 2, 3, 1)
return m
- 注意力匹配 (Attentive-Matching):首先根据句子$P$当前时刻的上下文表示向量对句子$Q$进行注意力权重计算,然后对$Q$的所有向量进行加权平均得到一个向量表示,再将句子$P$当前时刻的上下文表示向量与$Q$的注意力向量作为$f_m$的输入。其中论文采取$cosine$作为注意力权重计算的函数。
# 3. Attentive-Matching
# (batch, seq_len1, seq_len2)
att_fw = attention(con_p_fw, con_h_fw)
att_bw = attention(con_p_bw, con_h_bw)
# (batch, seq_len2, hidden_size) -> (batch, 1, seq_len2, hidden_size)
# (batch, seq_len1, seq_len2) -> (batch, seq_len1, seq_len2, 1)
# -> (batch, seq_len1, seq_len2, hidden_size)
att_h_fw = con_h_fw.unsqueeze(1) * att_fw.unsqueeze(3)
att_h_bw = con_h_bw.unsqueeze(1) * att_bw.unsqueeze(3)
# (batch, seq_len1, hidden_size) -> (batch, seq_len1, 1, hidden_size)
# (batch, seq_len1, seq_len2) -> (batch, seq_len1, seq_len2, 1)
# -> (batch, seq_len1, seq_len2, hidden_size)
att_p_fw = con_p_fw.unsqueeze(2) * att_fw.unsqueeze(3)
att_p_bw = con_p_bw.unsqueeze(2) * att_bw.unsqueeze(3)
# (batch, seq_len1, hidden_size) / (batch, seq_len1, 1) -> (batch, seq_len1, hidden_size)
att_mean_h_fw = div_with_small_value(att_h_fw.sum(dim=2), att_fw.sum(dim=2, keepdim=True))
att_mean_h_bw = div_with_small_value(att_h_bw.sum(dim=2), att_bw.sum(dim=2, keepdim=True))
# (batch, seq_len2, hidden_size) / (batch, seq_len2, 1) -> (batch, seq_len2, hidden_size)
att_mean_p_fw = div_with_small_value(att_p_fw.sum(dim=1), att_fw.sum(dim=1, keepdim=True).permute(0, 2, 1))
att_mean_p_bw = div_with_small_value(att_p_bw.sum(dim=1), att_bw.sum(dim=1, keepdim=True).permute(0, 2, 1))
# (batch, seq_len, l)
mv_p_att_mean_fw = mp_matching_func(con_p_fw, att_mean_h_fw, self.mp_w5)
mv_p_att_mean_bw = mp_matching_func(con_p_bw, att_mean_h_bw, self.mp_w6)
mv_h_att_mean_fw = mp_matching_func(con_h_fw, att_mean_p_fw, self.mp_w5)
mv_h_att_mean_bw = mp_matching_func(con_h_bw, att_mean_p_bw, self.mp_w6)
def attention(v1, v2):
"""
:param v1: (batch, seq_len1, hidden_size)
:param v2: (batch, seq_len2, hidden_size)
:return: (batch, seq_len1, seq_len2)
"""
# (batch, seq_len1, 1)
v1_norm = v1.norm(p=2, dim=2, keepdim=True)
# (batch, 1, seq_len2)
v2_norm = v2.norm(p=2, dim=2, keepdim=True).permute(0, 2, 1)
# (batch, seq_len1, seq_len2)
a = torch.bmm(v1, v2.permute(0, 2, 1))
d = v1_norm * v2_norm
return div_with_small_value(a, d)
- 最大注意力匹配 (Max-Attentive-Matching):和注意力匹配策略基本类似,区别是加权平均变成了取最大。
# 4. Max-Attentive-Matching
# (batch, seq_len1, hidden_size)
att_max_h_fw, _ = att_h_fw.max(dim=2)
att_max_h_bw, _ = att_h_bw.max(dim=2)
# (batch, seq_len2, hidden_size)
att_max_p_fw, _ = att_p_fw.max(dim=1)
att_max_p_bw, _ = att_p_bw.max(dim=1)
# (batch, seq_len, l)
mv_p_att_max_fw = mp_matching_func(con_p_fw, att_max_h_fw, self.mp_w7)
mv_p_att_max_bw = mp_matching_func(con_p_bw, att_max_h_bw, self.mp_w8)
mv_h_att_max_fw = mp_matching_func(con_h_fw, att_max_p_fw, self.mp_w7)
mv_h_att_max_bw = mp_matching_func(con_h_bw, att_max_p_bw, self.mp_w8)
最终,$P$对$Q$进行匹配可以得到一组向量,向量个数等于$P$的长度, 向量维度是$l\times 8$(4种匹配策略,双向LSTM),同理,$Q$对$P$进行匹配也可以得到一组向量。
# (batch, seq_len, l * 8)
mv_p = torch.cat(
[mv_p_full_fw, mv_p_max_fw, mv_p_att_mean_fw, mv_p_att_max_fw,
mv_p_full_bw, mv_p_max_bw, mv_p_att_mean_bw, mv_p_att_max_bw], dim=2)
mv_h = torch.cat(
[mv_h_full_fw, mv_h_max_fw, mv_h_att_mean_fw, mv_h_att_max_fw,
mv_h_full_bw, mv_h_max_bw, mv_h_att_mean_bw, mv_h_att_max_bw], dim=2)
mv_p = self.dropout(mv_p)
mv_h = self.dropout(mv_h)
4. Aggregation Layer¶
聚集层:使用另一个 BiLSTM,对匹配层得到的两组向量序列分别进行建模,并且都取最后时刻的向量。因此最终得到4个向量(两组*双向),将这4个向量连结作为输出。
# ----- Aggregation Layer -----
# (batch, seq_len, l * 8) -> (2, batch, hidden_size)
_, (agg_p_last, _) = self.aggregation_LSTM(mv_p)
_, (agg_h_last, _) = self.aggregation_LSTM(mv_h)
# 2 * (2, batch, hidden_size) -> 2 * (batch, hidden_size * 2) -> (batch, hidden_size * 4)
x = torch.cat(
[agg_p_last.permute(1, 0, 2).contiguous().view(-1, self.args.hidden_size * 2),
agg_h_last.permute(1, 0, 2).contiguous().view(-1, self.args.hidden_size * 2)], dim=1)
x = self.dropout(x)
5. Prediction Layer¶
预测层:通过两层全连接+softmax作为分类器, 激活函数使用$tanh$。
# ----- Prediction Layer -----
x = F.tanh(self.pred_fc1(x))
x = self.dropout(x)
x = self.pred_fc2(x)